Windows 11 + WSL2でRubyMineを動かす
Windows11をクリーンインストールしました。 WSL上で動くRubyMineのセットアップがとても簡単になっていたので紹介することにしました。 ほかの処理系のインストールを除けば、ほかのJetBrains系のIDEも同じ手順でできると思います。
なぜWSLでRubyMineを動かすのか
RubyをWindows環境で動かすと、おもに共有ライブラリなどでトラブルになることが多いです。Linux環境であるWSLでRubyの処理系を動かせたほうが、様々なトラブルに引っかかる可能性がなくなります。引っかかったとしても、たいていStackOverflowに答えが書いてあります。
Rubyの処理系がWSL上で動けばいいのなら、Windows上で動くRubyMineからWSL上で動くRubyの処理系だけを操作する、という方法もあります。私はこの方法で開発をしていたことがあるのですが、Windows側とWSL側で同期をとる必要があったり、正しく同期をとるためにいくらかの設定を必要とするなど、たびたび悩まされることがありました。
そこで、RubyMineそのものをWSLで動かして、WindowsとはX Window Systemを通じたGUIのやり取りのみを行うことにして、これらのややこしい問題を回避することにしました。 私はWindows 10のころから、WSL2とVcXsrvを利用してこの環境を作っていました。それまではいろいろと厄介なことになっていたWindows上での開発ですが、この環境にしてからエラーに見舞われることが少なくなりました。(X上での日本語の設定とかでたまに困ったりはした)
動作環境
Windows 11
やっていき
1 Microsoft StoreからWindows Subsystem for Linux Previewをインストールする https://aka.ms/wslstorepage
この時点でWSLgというX Window Systemが使えるようになる。すごい。
2 Microsoft StoreからUbuntuをインストールする https://aka.ms/wslstore
3 Ubuntuをセットアップする 起動すると最初のユーザーを作ることになるので、プロンプトの表示に従って進める。
4 WSLにRubyMineをダウンロードする 下記ページの"direct link"のリンクのアドレスをコピーする。 https://www.jetbrains.com/ruby/download/download-thanks.html?platform=linux
ダウンロードして解凍する
wget -O rubymine.tar.gz '[リンクのアドレス]' tar -xavzf rubymine.tar.gz sudo mv RubyMine-2021.2.3 /usr/local/share sudo ln -s /usr/local/share/RubyMine-2021.2.3/bin/rubymine.sh /usr/local/bin/rubymine
5 アクティベーションコードを入手する JetBrainsのアカウントページでDownload activation code for offline usageを押す https://account.jetbrains.com/licenses
6 起動してアクティベーションする rubymineを起動。
rubymine
Activation Codeのラジオボタンを選んで、5で入手したアクティベーションコードを入力する
7 日本語を使えるようにする
Win11のWSL2 (WSLg)を日本語化 & Mozcで日本語入力 | AsTechLog
8 RubyMineのUIに使うフォントを変更する なんかジャギジャギしたフォントになっているので、お好みのフォントに変更します。
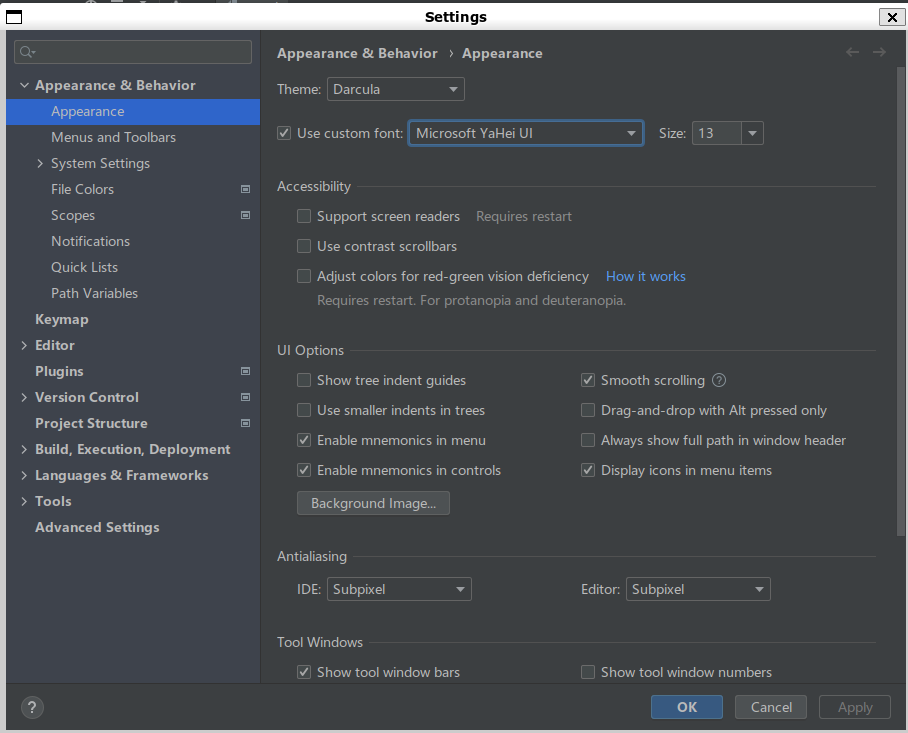
9 Windowsからショートカットを作る あったほうが便利
リンク先を下記に設定したショートカットを作る。
C:\Windows\System32\wsl.exe --distribution Ubuntu rubymine
結果
ということでこんな感じになりました。

いい感じのAction View用gemを作ったら、すでに提供されている機能だった
解決したかった問題
ActionViewで、条件付きで有効になるクラスを作ろうとすると、ややこしくなることがある。
buttonは常につけて、特定のコントローラーで処理しているときだけbutton-activeをつけたいとき、erbで頑張ると下記のようになる。
<a class="button<%= " button-active" if controller_name=="targets" %>"> # controller_name == "targets" => "button button-active" # controller_name != "targets" => "button"
この方法だと、ちょっと嫌な点がある
- 複数の条件付きクラスがあると読み解きにくくなる
- クラス名とクラス名の間のスペースをつけ忘れてはいけないので、メンテ時にうっかり消さないように注意が必要
作った
これをもう少し単純に書けないかと思ってgemを作った。
<a class="<%= html_class(:button, "button-active": -> { if controller_name=="targets" }) %>">
# controller_name == "targets" => "button button-active"
# controller_name != "targets" => "button"
スペースのことを気にしなくて良くなった。 複数の条件付きクラスがあっても、配列の表現に従った統一された記述ができるので読みやすい。 セマンティクス的にもわかりやすい。
あった
なんかいい感じなインターフェースが作れたなと思ってかなり満足感あったので、社内で宣伝した。
ソッコーで「それrailsにありませんでしたっけ」と教えてもらった。
rails6.1から、class_namesという名前のヘルパーメソッドが使えるようになっていた。
<a class="<%= class_names('button', { 'button-active': controller_name=="targets" }) %>">
下記のような細かい違いはあるものの、受けられる恩恵はだいたい同じ。
- html_classは条件付きクラスはキーワード引数として渡す。class_namesはハッシュとして渡す。
- html_classは条件を表すProcを受け取る。class_namesはブール値を受け取る。
さらに
class_namesで利用できる条件付きクラスの仕様は、ActionViewのtagメソッドでも利用できる。
つまり、link_toなどのrailsでclassを渡せるメソッドでは下記のように書ける。
<% link_to class=['button', { 'button-active': controller_name=="targets" }] %>
ActionView::Helpers::TagHelper
ちゃんとサンプルにも記載がある。
まじかよぉ(すごい)
なぜ作ってしまったのか
- テンプレート側で頑張るコードを仕事でたくさん見かけたので、そういうもんなんだという先入観から入った
- それでも半年くらい前にこういう機能無いかなって調べたけど、そのときは見つけられなかったので、無いもんだと思ってた(その時すでにあったはずだけど見つけられていなかった)
- アイディアを思いついたときにうわ俺天才じゃんってなって勢いで作ったので、再度類似のものが無いか調べなかった
- コードの量が少なく、簡単に実現できたので、まあカブってもそんな痛手じゃないやって思った。
得られたもの
世の中的には意味のないことをしてしまったのだけれど、個人としてはいろいろ得るものがあった。
- 人にgemを自慢すると、関連情報を教えてもらえることがわかった
- class_namesの実装のなかで、書いた人に共感しつつ、何を捨てて何を得ようとしたのかわかった
- 解決しようとしていた問題は同じなので、割とセンスあるかもしれないなって思えた
- 解決方法はclass_namesのほうがスマートだったので、自分よりすごい人のテクを深く味わえた
今後どうする
自分は結構得られたものが多くて嬉しかったのだけれど、使ってしまった人には迷惑を書けてしまうと思う。 ということで今後は下記をやる。
- READMEにclass_namesをつかってねと書く。
- gemを作るときは競合がないか調べる。
- でも調べても見つからないこともあるので、そのときはごめんなさい
- 開発途中のものをみてもらえるように、ミートアップや勉強会に顔を出すなど…
と思いつつ、カブったときのリスクが小さいときは、やっぱり書いちゃうかなと思った。
Peoplewareを読んだ
Tom Demarco & Timothy ListerのPeoplewareを読んだ。いまいち理解できていない部分が多いので、ここに書いて整理する。
要旨
ソフトウェア開発における課題の大半は技術的な問題ではなく社会学的なものである、という主張を核に、ソフトウェア開発のマネジメントがどうあるべきかを説いた本。
作業者が効率よく作業するために必要なことが説明される。具体的には、他人に邪魔されず集中すること、自発的に期限を設定できること、品質を高く保つ権限をもつことなどである。 また、チームとして動く場合に結束力を上げるためには、共通意識やコミュニティの醸成が不可欠であることを示している。
それらを実現するためには、どのようなマネジメントや環境の整備が必要なのか、著者の経験と外部の文献の調査結果を説明している。
1 人材を活用する
- 開発における問題の殆どは「人に関する問題」である
- 本来持っている能力(静的側面)と、チームに入ってから発揮できる能力(動的側面)は違う
- 頭を使う仕事では、手を動かさずじっくり考えることが重要
- 残業をすると、その分次の日のパフォーマンスが落ちる
- 品質を上げるとコストは下がる。が、品質を上げる権限を得ることは難しい
- 目標は無いほうが成果が出る
- マネジメントでするべきことは、部下のやる気を出させること
2 オフィス環境と生産性
- オフィスの品質は生産性と品質に悪影響を与える
- 残業の理由は、「量をこなすため」ではなく「品質を上げるため」
- プログラマーの生産性は、一緒に働くプログラマーとほぼ同じになる
- 一人で集中して誰にも邪魔されずに作業する時間が必要
- 良いアイディアは無音の空間で生まれる
- 同じチームの3,4人を一つの部屋に入れると、必要なときにコミュニケーションし、同時にフローに入れる
- オフィスに快適な環境が無いなら、外に借りてもいい
3. 人材を揃える
- 社内の標準に収まっているかどうかを気にしない
- リーダーシップとは、全員に最大の価値を与えるような仕事を自ら仕事を引き受けたときに生まれる
- 採用プロセスでは、できるだけ実際の能力がわかるような成果を見せてもらう
- 人間的な能力も見たほうがいい
- 人がやめたときのコストは大きい
4. 生産性の高いチームを育てる
- チームに仕事をさせるのではなく、一体感をもたせる
5. 肥沃な土壌
- リスクを考えるときに、自分が責任を全うできなかった場合も考える
- 会議は儀式になりやすい
- 組織の学習能力は、どれだけ人を引き止めておけるかで決まる
6. きっとそこは楽しいところ
- 社員が楽しくいられるような出来事を与える
- プログラミングコンテスト、パイロットプロジェクト、旅行など
感想
プログラマーの成果は、かけた時間ではなく、誰にも邪魔されずに連続して集中できた時間で決まる、という主張がはっきり述べられていたのが印象的だった。これはすぐに仕事に活かせそう。全体的に、マネジメント担当者に向けて書かれているので、自分の仕事のポジション的にすぐに役立てられそうな話題は少ないように感じた。
個々の話題について、あまり具体的な解決策が示されているように感じなかった。なので、それで結局どうすればその課題は解決できるの?という疑問が解決されないまま話が進んでいくように感じた。
基本的な原理は示したので、あなたが考えてくださいねという投げかけなのだと思う。
出版から30年近く経っているので、とても目新しい考え方を目にするということは少なかった。これは、後続の本や開発プロセスに、この本が影響を与えているからだろう。この本の功績を物語っていると考えるべきだろう。
Minecraft統合版サーバーを立ててNintendo Switchからも遊べるようにする
環境
Windowsで立てたサーバーに、ローカルネットワーク内の統合版のマイクラからアクセスして遊べるようにしたい。
サーバー: 統合版サーバー (マシン: Windows 10 自作PC)
クライアント: マインクラフト統合版(マシン: Windows 10, Android, iPad, Switch)
クライアントはすべてサーバーと同じローカルネットワーク内にある
やること
- 統合版サーバーを立ち上げる
- Windows機からサーバーに入れるようにする
- Switchからサーバーに入れるようにする
Bedrock Edition - Minecraft Wiki
統合版サーバーを立ち上げる
- Windows用サーバーソフトウェアをダウンロードする https://www.minecraft.net/ja-jp/download/server/bedrock
- zipファイルを解凍する
- Windows Defenderファイヤウォールで、解凍したフォルダ内のbedrock_server.exeを許可する
- bedrock_server.exeをダブルクリックで起動する
全体の手順はこちらが詳しい。
【マイクラ統合版】自前サーバーの立て方をやさしく解説! | WEBレコ
Windows Defenderファイヤウォールの設定手順はこちらが詳しい。
Windowsファイアウォールの例外にアプリケーションを追加する方法 | バッファロー
ゲーム内の設定についてはこちらが詳しい。設定したらbedrock_server.exeを再起動する。
マインクラフト(MINECRAFT)統合版サーバーの設定 | LIFEWORK Blog
Windows機からサーバーに入れるようにする
サーバーとして使っているマシンでマインクラフトを起動してサーバーにアクセスできるようにする。
管理者権限でコマンドプロンプトを立ち上げて、下記を実行する。
CheckNetIsolation.exe LoopbackExempt –a –p=S-1-15-2-1958404141-86561845-1752920682-3514627264-368642714-62675701-733520436
マインクラフト統合版(クライアント)を立ち上げて、遊ぶ→サーバー→サーバーを追加
- サーバー名: local
- サーバーアドレス: 127.0.0.1
- ポート: 19132
追加したサーバーをクリックするとワールドに入れる。
この時点で、同じネットワーク内にあるスマホ、タブレット、PCの統合版マインクラフトからもサーバーにアクセスできる。 しかし、Nintendo Switchなどのコンシューマーゲーム機はアクセスできない。プラットフォーム間の差異についてはこちらが詳しい。
Bedrock Edition - Minecraft Wiki
Switchからサーバーに入れるようにする
Switchでは、IPアドレスを指定してサーバーにアクセスすることができない。ただし、特集サーバーにはアクセスできる。
そこで、下記のような設定を行えば自分の立てたサーバーにアクセスできる。
- ローカルネットワーク内にDNSサーバーを立てる
- DNSサーバー側で特集サーバーのドメインを自分が立てたサーバーのIPアドレスにひもづける。
- Switchで、自分が立てたDNSサーバーで名前解決するように設定する
下記のリポジトリのREADMEに従うと、上記の設定が行える。
GitHub - ConnorGraham/Minecraft-Nintendo-Switch-Private-Server
docker desktopを使う場合、Docker Desktop Backendがファイヤウォールで弾かれていないか確認しておく。 設定ができたら、switchからLifeboat のサーバーに入ると、自分の立てたサーバーにアクセスできる。
Minecraftのポリシー的にセーフなのかは確認していないので、手法とリポジトリの紹介にとどめておく。
補足
上記では、特定のサーバーに飛ばすような設定を紹介したが、任意のサーバーにアクセスする手法もある。
下記のリポジトリでは、READMEに記載のDNSサーバーを使うことで、任意のサーバーにアクセスできることを紹介している。
自分でDNSサーバーを建てる必要なく任意のサーバーにアクセスできるので簡単。ただし、海外の有志が提供するサーバーを利用することになるため、セキュリティ上のリスクがあることには注意する。
まとめ
面倒なのでRealmsを買うといい。
YouTube Data APIを使って登録者の少ないYouTubeチャンネルを探す
YouTubeからデータを取得しまくってアプリケーションを作ろうと思っていたが、一日あたりにリクエストできる量が限られていて結構厳しくて頓挫した。 アプリケーションを作る前にやりたいことができるのか確かめるためにスクリプトを書いたので、供養のために記事にしておく。
背景
いわゆる底辺Youtuberを見つけて応援したかった。 しかしながら、彼らを効率的に探す方法が見当たらなかった。
頑張って人力で探す方法は下記ページにまとめられている。
底辺ユーチューバー 探し方4選 見つけ方 YouTuber 登録数が少ない | 知恵袋wikiまとめ
そこで、YouTubeのAPIを使うことで、効率的に底辺YouTuberを見つけることができないか試した。
やりたいこと
底辺YouTuberには明確な定義がないので、探す対象を「登録者が少ないが、活発に活動しているYouTubeチャンネル」とした。
「登録者が少ないが、活発に活動しているYouTubeチャンネル」を、仮に次のように定義した。
- 登録者が1万人以下
- 直近一ヶ月の動画投稿数が15本以上
YouTube Data API
YouTube Data APIは、Youtubeが公式に提供しているAPI群。 情報収集や分析に必要なAPIは一通り揃っている。
API Reference | YouTube Data API | Google Developers
利用制限
GCPのアカウントがあれば誰でも利用できる。クォータと呼ばれる利用上限を設けている。クエリごとに消費するクォータが異なるが、ざっくりいうと多くの情報を取得するほどクォータを消費する。
YouTube Data APIのクォータ数増加申請が通った件の振り返り - Qiita
クォータは、GCPのコンソールの「IAMと管理」→「割当て」から確認できる。

取得方法の設計
次の手順で、「登録者が1万人以下かつ直近一ヶ月の動画投稿数が15本以上チャンネルのリスト」を得る。
Search: list APIを用いて、すべてのチャンネルのIDを得る https://developers.google.com/youtube/v3/docs/search/list
Channels: list APIを用いて、1. で得たチャンネルの登録者数とアップロード動画リストのIDを取得する Channels: list | YouTube Data API | Google Developers
2で得た登録者数を用いて1のチャンネルリストを登録者数1万人以下のものに絞り込む
3で得たチャンネルのアップロード動画リストIDを用いて、アップロード動画を取得する
4で得たアップロード動画リストを用いて、一ヶ月の動画投稿数が15本以上のチャンネルを絞り込む
結論から言うと、この設計ではうまく行かない。1のチャンネルの取得の時点で、簡単に利用制限に引っかかってしまう。このため、APIリクエストの少ない別の方法が必要になる。
2まで作ってうまく行かないことに気がついたので、次節移行に、以下に2までをrubyで実行する方法を示す。
下準備
YouTube Data APIを使う前に、下記の準備が必要。
こちらのページに詳しく記載されている。
APIを色々たたいて実験したかったのでAPIドキュメントをよみつつpostman を利用した。 postmanの利用でもクォータは消費されるので注意する。
Search: list APIを用いて、すべてのチャンネルのIDを得る
API通信にfaradayを使いたいのでインストールしておく。
gem install faraday faraday_middleware
search: list APIを利用して、チャンネルを50件ずつ取得する。
- 本来は取得できる全量を取得したいが6×50で300件としておく。
- next_page_tokenを使ってページネーションするので、取得結果とセットで同じオブジェクトにまとめる
require 'faraday' require 'faraday_middleware' class ChannelResult attr_reader :channels, :next_page_token def initialize(channels, next_page_token) @channels = channels @next_page_token = next_page_token end end def fetch_channels(next_page_token = nil) url = "https://www.googleapis.com/youtube/v3/search?part=id&type=channel&maxResults=50®ionCode=JP&key=#{API_KEY}" conn = Faraday.new(url: url) { |faraday| faraday.adapter Faraday.default_adapter faraday.response :json } response = conn.get(nil, "pageToken" => next_page_token) pp response.body channels = response.body["items"].map { _1["id"]["channelId"] } next_page_token = response.body["nextPageToken"] ChannelResult.new(channels, next_page_token) end def channels t = nil (1..6).flat_map do resp = fetch_channels(t) t = resp.next_page_token resp end end puts channels
Channels: list APIを用いて、チャンネルの登録者数を取得する
- idを指定することで、まとめて50件取得できる
- レスポンスの構造はドキュメントを見て把握する
class ChannelDetail attr_reader :id, :subscribers, :title def initialize(id, subscribers, title) @id = id @subscribers = subscribers @title = title end def format "#{title} #{subscribers}" end end def channel_details(list) ids = list.channels.join(",") url = "https://www.googleapis.com/youtube/v3/channels?part=statistics,snippet&id=#{ids}&key=#{API_KEY}" conn = Faraday.new(url: url) { |faraday| faraday.adapter Faraday.default_adapter faraday.response :json } response = conn.get response.body["items"].map do ChannelDetail.new( _1["id"], _1["statistics"]["subscriberCount"], _1["snippet"]["title"] ) end end def ch(channel_lists) channel_lists.flat_map do |list| channel_details(list) end end details = ch(channels) sorted = details.sort_by do _1.subscribers.to_i end
実行すると、こんなかんじでランキング形式でチャンネルと登録者数を得られる

コード全量
問題点
API呼び出しとデータ取得の量が多すぎるため、一瞬でクォータの上限に達する。
今後
少ないAPI呼び出して所望のチャンネルを得られるような工夫をする。 searchの時点である程度絞れるようにするとよさそう。
システム設計って何すりゃいいの? ~System Design Primerを読んでみる~
System Design Primer
https://github.com/donnemartin/system-design-primer
システムをスケールさせるためのアーキテクチャ構成の仕方を学べる資料集。 主に、パフォーマンスの要求に応えられるようにするにはインフラをどのように組み合わせればよいのか、という点について詳しく説明している。 日本語版もあります。
システム設計とは
一般的なシステム設計は、システムを構築するためのあらゆる設計を指しますが、ここではもう少し狭い意味で使います。
主に、下記を満たすためのインフラ構成とスケールの仕方を考えることを指すこととします。 - ユースケースを実現する - パフォーマンスの要件を満たす
システム設計の流れ
システムの性能を上げるための知識
考え方
システム構成を考えるときは、必ずトレードオフの関係に注意する。パフォーマンスが上がる代わりに管理が難しくなるなど、いろいろなトレードオフが存在する。要件と照らし合わせて、何を達成して何を妥協するのかを考える。
CDN
CDNは地理的に一番近いサーバーからファイルを取得できるようにするシステム。主に静的ファイルを高速に配信するために利用する。
ロードバランサー
複数の同じ役割を持つサーバーへのリクエストを分散させるための機器。主にアプリケーションサーバーへのリクエストを振り分けて負荷を均一にするのに利用する。
リバースプロキシ
キャッシング、静的コンテンツの配信、SSLの終端などをアプリケーションサーバーの代わりに行うためのWebサーバー。 ロードバランサーと同様に、複数のアプリケーションサーバーをまとめることもできる。
RDBMS
構造化されたデータを扱うデータベース。トランザクションを扱えるので、データの整合性を保ちやすい。 スケールする際は、レプリケーションを用いてデータベースの数を増やして負荷を分散したり、シャーディング、フェデレーションによって一度に扱うデータの数を減らしたりする。
NoSQL
完全には構造化されていないデータを扱うデータベース。主に結果整合性しか保証しない。 基本的に、大容量のデータを扱うなど、特定の適した用途に局所的に利用する。
キャッシュ
キャッシュはいろいろな場面で高速な応答をするのに用いられる。 キャッシュアサイド、ライトスルー、ライトバックといったキャッシュ方式がある。キャッシュを導入するとシステムの複雑性は増す。
非同期処理
重たい処理を別のシステムに移譲するなどして、後で実行する。 メッセージキューを使ってジョブの要求を伝達する。
システムの構成
マイクロサービス
独立してデプロイ可能な小さなサービスの集合としてアプリケーションを構成する手法。サービス単位でスケールできるので、スケールしやすい。
サービスディスカバリー
主にマイクロサービス構成で、サービス同士がお互いを見つけやすくする仕組み。クラウド環境のようにサービスのIPアドレスや構成が変わるような環境での管理をしやすくするために用いられる。
システム設計問題を解いてみる
実践TDD 第一章
テスト駆動開発のポイントとは?
- システム開発は、作ろうとしているものへの理解を深めながら進行する
- システムとその用途を学ぶためには、作ってリリースしてフィードバックを得るのが良い
- 実装する前にテストをすることで設計する。何をさせたいかが明確になる。同時に、リグレッションテストを行えるので更新のコストとリスクを小さくできる。
- 完了の定義が明確になる。コンポーネントが疎結合になる。コードが何をするかの説明が得られる。
- 必要なものを必要な分だけ実装できる
- E2Eの受け入れテストを書くところからはじめるといい
- 外側の質とは、顧客のニーズにどれくらい答えられているか。E2Eテストで確認する。
- 内側の質は、管理者や開発者のニーズにドラくらい答えられているか。ユニットテストで確認する。
- ユニットテストを書くことで内部品質は向上する。