AIに最近のエンジニアブログについてツイートさせてみた
この記事は SmartHR Advent Calendar 2023 2nd の13日目の記事です。
エンジニアブログについてのツイート
最近、Xで定期的にこんなツイートをしています。

これはOpenAI APIを使って自動生成したツイートです。 もともと自分でブログを読んで備忘用にツイートをしていたのですが、下記のような背景から自動化してみることにしました。
- OpenAI APIがとても流行っていて、そう遠くないうちに仕事などで使うことになりそうなので何か作ってみたかった
- いい記事を見つけてもツイートをする気力が無くて断念してしまうことがあった
- AIに自動でツイートさせて、良くないものは事後チェックして消す運用をすれば、今までとそこまで変わらない備忘録が作れるのではないかと考えた
構成
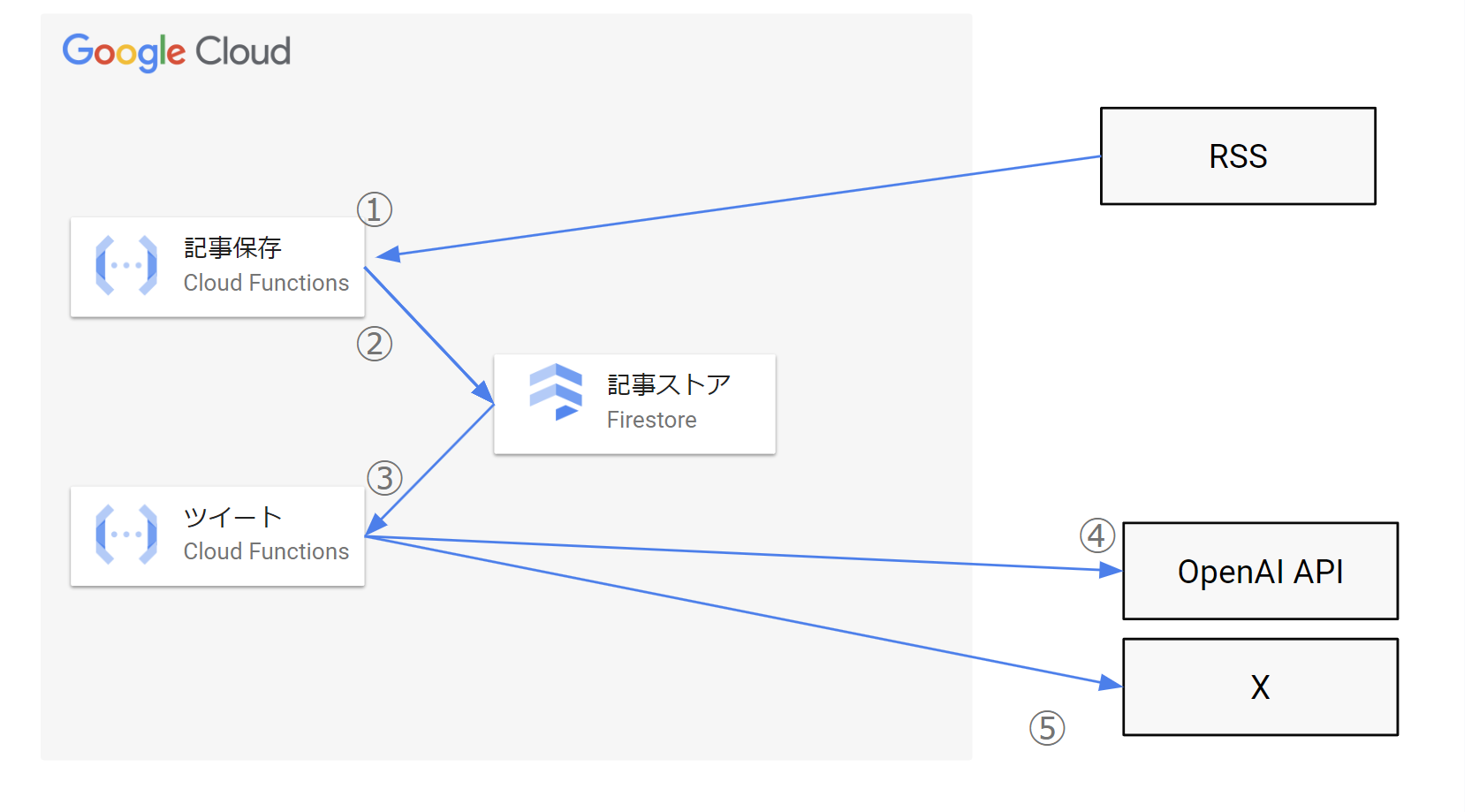 ツイートは2つのCloud Function関数とDatastoreモードのFirestoreを使って実装しています。
ツイートするまでの流れは下記のとおりです。
ツイートは2つのCloud Function関数とDatastoreモードのFirestoreを使って実装しています。
ツイートするまでの流れは下記のとおりです。
- ①記事保存用の関数で、企業テックブログRSSから記事のタイトル、概要、URLを取得します。
- ②取得した記事の情報をFirestoreに保存します。
- ③ツイート用の関数で、Firestoreから記事情報を取得します。
- ④OpenAI APIに記事情報付きのプロンプトを与え、ツイートを生成します。
- ⑤取得したツイートをXに保存します。
同じ記事についてのツイートを複数回してしまう可能性があるので、下記の動作によって防止しています。
- ⑤のあとに、ツイートの対象となった記事のデータに、ツイート済みであることを示すプロパティを付与します。
- ③の記事取得時に、ツイート済みの記事は取得しないようにします。
- ②で、すでに取得済みの記事は再度取り込まないようにします。
Cloude Schedulerを用いて、記事保存用の関数を1時間ごと、ツイート用の関数を日中に5時間ごとに実行しています。
記事保存用関数
関数はRubyで書いています。 RSSから必要な情報を取得してDatastore(DatastoreモードのFirestore)に保存します。 postedプロパティは、記事がツイート済みであることを表すプロパティで、取り込み時はまだツイートしていないのでfalseにします。
ソースコード
require "functions_framework" require "google/cloud/datastore" require "rss" require "open-uri" FunctionsFramework.http "aggregate" do |request| datastore = Google::Cloud::Datastore.new project_id: project_id url = 'https://yamadashy.github.io/tech-blog-rss-feed/feeds/rss.xml' articles = nil URI.open(url) do |rss| feed = RSS::Parser.parse(rss, false) articles = feed.items.map do |item| key = datastore.key "Article", item.link article = datastore.entity key do |a| a["title"] = item.title a["link"] = item.link a["description"] = item.description a["date"] = item.date a["posted"] = false end if datastore.find(key).nil? article else nil end end.compact end datastore.save(*(articles.uniq { |a| a.key.name })) "OK" end
ツイート用関数
ツイート用関数のやっていることは主に3つです。
- Firestoreから記事情報を取得する
- OpenAI APIでツイートを生成する
- ツイートする
OpenAI APIでツイートを生成する
下記のようなプロンプトを送ってツイートを生成させます。 モデルはGPT-4 Turboを使っています。
次の手順で、エンジニアのツイートを生成してください 1. 「最近の記事」 を参照してニュースの記事の一覧を取得する 2. 一覧の中から、ニュースを一つ選ぶ。選ぶニュースの優先度は、Rubyに関係するもの、関係者が多いもの、AIに関連するもの、の順にしてください。 3. 選んだニュースを完結にまとめて、感想を含めて100字以内のツイートにしてください。 口調は独り言っぽくしてください。あまり絵文字は使わず、まじめで信憑性が高そうな文章にしてください。ハッシュタグは1つも含めないでください。返答はツイートの内容のみで、それ以外の区切りの記号などは含めないでください。 選んだ記事のURLをツイートに含めてください 最近の記事 Title:いいかんじの技術をいい感じにしました Description: いい感じの技術っていいですよね。こんにちは。 URL: https://iikanji.test/article/iikannji-ha-iikannji (以下20個くらいつづく)
ツイートの長さの支持は100文字としています。Xは140字までツイートできますが、URLで12文字、AIの投稿であることを伝える文言が12文字あるのと、たまに暴発してちょっと文字数が増えることがあるためです。
ソースコード
require "functions_framework" require 'google/cloud/datastore' require 'x' require 'openai' x_credentials = { api_key: ENV['X_API_KEY'], api_key_secret: ENV['X_API_KEY_SECRET'], access_token: ENV['X_ACCESS_TOKEN'], access_token_secret: ENV['X_ACCESS_TOKEN_SECRET'] } x_client = X::Client.new(**x_credentials) store = Google::Cloud::Datastore.new(project_id: project_id) FunctionsFramework.http "tweet" do |request| article_data = "" items = store.run(store.query("Article").order("date", :desc).limit(20)).filter do |article| !article["posted"] end items.each do |item| article_data << "Title: #{item["title"]}\n" article_data << "Description: #{item["description"]}\n" article_data << "Link: #{item["link"]}\n" article_data << "---\n" end prompt = <<~PROMPT 次の手順で、エンジニアが興味を引くツイートを生成してください 1. 「最近の記事」 を参照してニュースの記事の一覧を取得する 2. 一覧の中から、ニュースを一つ選ぶ。選ぶニュースの優先度は、Rubyに関係するもの、関係者が多いもの、AIに関連するもの、の順にしてください。 3. 選んだニュースを完結にまとめて、感想を含めて100字以内のツイートにしてください。 口調は独り言っぽくしてください。あまり絵文字は使わず、まじめで信憑性が高そうな文章にしてください。ハッシュタグは1つも含めないでください。返答はツイートの内容のみで、それ以外の区切りの記号などは含めないでください。 選んだ記事のURLをツイートに含めてください 最近の記事 #{article_data} PROMPT openai_client = OpenAI::Client.new(access_token: ENV['OPENAI_API_KEY']) responce = openai_client.chat(parameters: { model: "gpt-4-1106-preview", messages: [{ role: "user", content: prompt }], }) tweet = responce.dig("choices", 0, "message", "content") url = tweet.scan(/https?:\/\/[\S]+/)[0] a = store.find("Article", url) raise "urlがうまいことパースできなかった" unless a a["posted"] = true store.save a x_client.post("tweets", "{\"text\": \"#{tweet + " 🤖AIによる自動投稿です}\"}") [200, {}, [tweet]] end
生成されるツイート
うまくいった例
いずれもちょっと鼻につく感じなのが玉にキズですが、それらしい文章が生成できています。
- AWS re:Invent 2023でのインフラコード管理のセッションが印象的。IaCの進化には目を見張るものがある。技術はどんどん前進しているな。 https://techblog.ap-com.co.jp/entry/2023/12/09/152039
- Microsoft Copilot Studioに触れた感想がある記事が気になるな。AIを補助ツールとしてどう生かすかが大切。アイデア増幅器としての可能性がある。https://aadojo.alterbooth.com/entry/2023/12/09/113106
うまくいかなかった例
140文字を超えてしまうことがあります。この場合はXのAPIに弾かれてツイートに失敗します。
- Rubyに関する直接の記事はないみたいだけど、AIが絡んでいる話題なら「パーソナライズド動画推薦システムをつくる | Gunosyデータ分析ブログ」というのがあるね。動画推薦エンジン、色々な要素を考慮してユーザーに合わせたコンテンツを提示してるんだって。技術の進歩って本当にすごいよね。興味深い内容だし、勉強にもなりそうだ。記事はこちらから読めるよ https://data.gunosy.io/entry/create_personalized_video_recommendation_system
出力に関しての説明を含めてしまうこともあります。
- RubyやAIに関する直接的な記事は一覧にありませんが、技術者の教育についての内容が含まれる記事を選択しました。未経験からエンジニアになる苦労や学びを、GameWithが公開。管理者目線の教育法、役立つね。https://tech.gamewith.co.jp/entry/2023/12/11/180333
まとめ
- OpenAI APIを使ってツイートを自動化したよ
- いうことを聞いてくれないこともあるよ
OpenAI APIは非常に簡単に使うことができて、ChatGPTを使っているのとあまり変わらない感触でした。スゴイですね! AIなにもわからねぇ~、と漠然とした苦手意識があったのですが、簡単に動くものが作れることがわかり、もっといろいろ作ってみたい!という気になれました。
RELATIONAL DATASET REPOSITORYのデータセットをPostgreSQLに取り込む
Relational Dataset Repositoryで、リレーショナルデータベース用のデータセットが公開されている。データセットによっては100万件ちかくのデータが入っているので、クエリ最適化などの練習に使えそう。
下記のデータセットをPostgresSQLに取り込んでみることにした。
https://relational.fit.cvut.cz/dataset/Financial
やること
データは公開されたMySQLのサーバーに入っていて、そこから適宜dumpしてね、という形で配布されている。このため、MySQLに保存されているデータをどうにかしてPostgreSQLに取り込む必要がある。
手順
下記の手順でデータを取り込む。
- mariadbをインストール
- pgloaderをインストール
- postgresのパスワード方式をmd5にする
- postgresに取り込み用のデータベースとユーザーを作成する
- pgloaderでデータを取り込む
mariadbをインストール
配布元のサーバーはmariadbで動いているので、互換性の問題が起きにくいようにmariadbをインストールする。
sudo apt install mariadb-client-10.3
pgloaderをインストール
MySQLのサーバーからPostgreSQLのサーバーに直接データを取り込むツール、pgloader をインストールする。
sudo apt install pgloader
postgresのパスワード方式をmd5にする
最近のpostgresは、デフォルトで暗号化方式がscram-sha-256になっているが、pgloaderは対応していない。md5で暗号化するように設定して認証できるようにする。
- postgresql.confに
password_encryption = md5を追記する - pg_hba.confでscram-sha-256をmd5に書き換える
- postgresを再起動
postgresに取り込み用のデータベースとユーザーを作成する
createdb financial createuser dump
superuserなユーザーでpsqlを起動
ALTER ROLE dump WITH PASSWORD 'dump';
pgloaderでデータを取り込む
pgloader mysql://guest:relational@relational.fit.cvut.cz/financial postgresql://dump:dump@localhost/financial
参考資料
便利なリレーショナルデータベースのオープンデータセット:RELATIONAL DATASET REPOSITORY – SHIN総研
pgloader 10 fell through ECASE expression · Issue #1183 · dimitri/pgloader · GitHub
PostgreSQLのデータファイルの中身を確認する
Postgresのマニュアルに、データファイルのレイアウトが載っていた。 www.postgresql.jp
テーブルに行を挿入して、実際に書き込まれるデータを確認してみる。
手順
データファイルのパスを調べる
テーブルを作成して、テーブルのファイルパスを調べる。
CREATE TABLE datafiletest (name varchar(100), age integer); SELECT pg_relation_filepath('datafiletest'); -- base/16388/24577 SHOW data_directory; -- /var/lib/postgresql/15/main
postgresのデータディレクトリからのパスが返ってくるので、データファイルは/var/lib/postgresql/15/main/base/16388/24577にあることがわかる。
データファイルの更新を確認する
デーブルを作成した時点ではファイルは空。0バイト。
postgres@TANAKA-DESKTOP:/home/ytnk531$ ls -l /var/lib/postgresql/15/main/base/16388 /24577 -rw------- 1 postgres postgres 0 1月 5 18:17 /var/lib/postgresql/15/main/base/16388/24577
データを追加する。 この時点ではWAL(先行書き込みログ)が記録されただけで、データファイルへの反映はされないので、CHECKPOINTを使って強制的にデータファイルを更新する。
INSERT INTO datafiletest VALUES('test', 10);
CHECKPOINT;
postgres@TANAKA-DESKTOP:/home/ytnk531$ ls -l /var/lib/postgresql/15/main/base/16388 /24577 -rw------- 1 postgres postgres 8192 1月 5 18:30 /var/lib/postgresql/15/main/base/16388/24577
このデータファイルには、今のところ1ページ分だけ書き込まれている。 マニュアルを頼りに読んでいく。 70.6. データベースページのレイアウト
まずヘッダ部分を確認するために、32バイトだけ読む。
postgres@TANAKA-DESKTOP:/home/ytnk531$ hexdump -C -n 32 /var/lib/postgresql/15/main /base/16388/24577 00000000 00 00 00 00 e8 85 9a 01 00 00 00 00 1c 00 d8 1f |................| 00000010 00 20 04 20 00 00 00 00 d8 9f 48 00 00 00 00 00 |. . ......H.....| 00000020
PageHeaderData 00 00 00 00 e8 85 9a 01 00 00 00 00 1c 00 d8 1f 00 20 04 20 00 00 00 00
- pd_lsn 00 00 00 00 e8 85 9a 01
- pd_checksum 00 00
- pd_flags 00 00
- pd_lower 1c 00
- pd_upper d8 1f
- pd_special 00 20
- pd_pagesize_version 04 20
- pd_prune_xid 00 00
pd_upperが、空き領域の終わりのアドレスを指す。リトルエンディアンなので、1fd8を指している。
ItemIdData
d8 9f 48 00
1アイテム分。
postgres/itemid.h at c8e1ba736b2b9e8c98d37a5b77c4ed31baf94147 · postgres/postgres · GitHub
- オフセット 11011000 0011111 -> 1f d8
- フラグ 10
- 長さ 1001000 00000000 -> 8 bytes
一つ目のレコードまでのオフセットが1fd8なので、データは1fd9から始まることがわかる。
postgres@TANAKA-DESKTOP:/home/ytnk531$ hexdump -C -s 8152 /var/lib/postgresql/15/ma in/base/16388/24577 00001fd8 eb 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00001fe8 01 00 02 00 02 09 18 00 0b 74 65 73 74 00 00 00 |.........test...| 00001ff8 0a 00 00 00 00 00 00 00 |........| 00002000
HeapTupleHeaderData eb 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 00 02 00 02 09 18 00
- t_xmin eb 02 00 00
- t_xmax 00 00 00 00
- t_cid 00 00 00 00
- t_xvac なし?(t_cidとt_xvacは共用体)
- t_ctid 00 00 00 00 01 00
- t_infomask2 02 00
- t_infomask 02 09
- t_hoff 18
hoffが18なので実際のデータは1ff1から始まる。
postgres@TANAKA-DESKTOP:/home/ytnk531$ hexdump -C -s 8177 /var/lib/postgresql/15/ma in/base/16388/24577 00001ff1 74 65 73 74 00 00 00 0a 00 00 00 00 00 00 00 |test...........|
- name 74 65 73 74 -> test
- age 00 00 00 0a -> 100
なんやかんや読み取れた。 後ろの4バイトは何なのかわからない。
nameを長くすると、いい感じに後ろに詰まる。4バイトごとにalignされている。
postgres@TANAKA-DESKTOP:/home/ytnk531$ hexdump -C -s 8177 /var/lib/postgresql/15/main/base/16388/24588 00001ff1 74 65 73 74 65 64 62 65 00 00 00 0a 00 00 00 |testedbe.......| 00002000
AWS SAAに合格した
AWS SAA合格しました、わーい 準備期間は2週間、勉強時間は12時間でした。 周辺知識や基礎的な理屈はもともとも知っているので、勉強時間少なくて済んだ模様。
教材
- 【SAA-C03版】これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座 | Udemy
- (模擬問題付き)改訂新版 徹底攻略 AWS認定 ソリューションアーキテクト − アソシエイト教科書[SAA-C02]対応 | 鳥谷部 昭寛, 宮口 光平, 菖蒲 淳司, 株式会社ソキウス・ジャパン |本 | 通販 | Amazon
- SAA | TechStock|AWS WEB問題集で学習しよう
- 【AWS資格】無料WEB問題集&徹底解説 | ソリューションアーキテクト(SAA)
所感としては、教材は1と2で十分だった。問題集は1にくっついている3つの問題集で十分で、あとはその3つで触れられているサービスを深く理解するのに時間を使えばよい。
勉強方法
- Udemyの教材(教材1)についている問題集を解く
- わからなかったところをについて、教科書(教材2)と問題の解説を照らし合わせながらインプットする
- 実際の設定方法のイメージがつかめないところはUdemyの教材のハンズオン動画を見る
- 問題集を解く
解いた問題集 - 教材3の無料分。20問くらい - 教材4の1~50くらい - Udemyの教材に添付の問題集のうち1つ
Udemyの教材に添付の3つの問題集を3周くらいするつもりだったが、実際は1つ目の問題集の半分くらいまでしかできなかった。
受験
渋谷テストセンターで受験した。 受け付けや試験の準備は、1人の担当者が複数人を同時進行で行っているため、少しだけ待ち時間があった。 本来の試験時間より30分早く着いたが、受付を済ませたらすぐ始めてOKだった。 終わったら退出してOK。 140分の試験時間のうち、80分くらいで回答して終了した。
所感
再受験が無料だったので、ダメもとで1回受けてみるかー、という感じで受けたら受かった。 本当は勉強方法4で演習をもっとやるべきだったのだが、全然できていなかったので反省。いまいち自身が無いまま試験に挑んだ。 次こういうのを受けるときは、すくなくとも問題集を解ききってから受験の日程を組むようにしたい。
テストセンターでの受験は、受付がすこし煩わしく感じたが緊張感があってよかった。でも次は多分自宅で受験する。
RubyKaigi 2022 Ruby meets WebAssembly
Ruby meets WebAssembly - RubyKaigi 2022
RubyKaigi 2022 1日目のキーノートが、内容もプレゼンも大変良かったので、少し詳しくレポートします。RubyをWebAssembly (WASM) の対応についてお話頂きました。WebAssemblyの基礎から、WebAssembly対応のテクニカルな難しさまで、非常にわかりやすく丁寧に説明されており、聴きごたえのある素晴らしい発表でした。 特にデモがおもしろく、思わずスゴイ!とうなりたくなるものばかりでした。
主な発表内容は、下記の3つでした。
RubyをWASM対応させるメリット
WASMは、主にWebブラウザで利用することを目的として作られた言語です。直接記述するのではなく、他の言語をWASMにコンパイルして使うことを想定して設計されています。
Rubyを動かすためにはまず環境構築が必要ですが、OSや実行環境によってトラブルシュートが必要になることもあります。
RubyがWASMで動くようになれば、WebブラウザさえあればRubyを実行できます。環境構築のハードルぐんと下げてRubyの間口を広げるとともに、より多くの用途でRubyを使えるようになります。
例えば、WASMはWebブラウザだけでなく、エッジコンピューティングなどで利用することもできるようになっきています。RubyをWASM対応させておけば、WASMさえ動く環境であればRuby用の個別の対応をいれずとも自動的にRubyを使えるプラットフォームが増えていきます。乗るしかねえ、このビッグウェーブに、というやつです。
WASM対応の仕組み
RubyをWASMで動かす際は、主に2つのリソースを使います。
ブラウザでWASMで書かれたRubyインタプリタを動かして、そこにRubyのソースコードを入力として与えます。
ここで注意したいのが、WASMさえあればRubyが行う全ての操作を実現できてしまうわけではない点です。WASMでは、システムのリソース(時計、ストレージなど)を操作する方法は定義されていません。
Webブラウザで動かす場合は、システムのリソースはJavaScript(JS)を使えば解決します。しかしながら、WASMはいろいろな環境で動かすことを想定するようになってきたので、JSに依存しない仕組みを作ろうということに成りました。そこで開発されたのがWASIです。WASIは、WASMからシステムのリソースへのインターフェースを定義する規定です。このおかげで、WASMとWASIを実装している環境であれば、WASMからシステムのリソースを操作できることになります。
RubyのWASM対応でも、WASIを利用してシステムのリソースを操作します。
RubyのWASM対応にあたって特に工夫した点
Rubyのインタプリタは、C言語で書かれていてます。C言語をWASMに変換できるコンパイラは既に存在しています。しかしながらRubyでは、単純には変換できない実装が3つありました。発表者の方は、「3つのドラゴン」と表現していました。
3つのドラゴン
setjmp/longjmpとFiberは、CRuby上でアセンブリを使って実装された特殊な実行フローの制御を行っている点が難しい点だったようでうす。CRubyでは、C言語を普通に書いていては実現できないような制御を、CPUアーキテクチャごとにアセンブリを書いて実装していました。WASMには対応する命令がないので、もとの実装に対応するWASMのコードを実装できない、という難しさがあります。
GCのためのレジスタスキャンは、通常WASMでは扱うことができない領域に対する領域にアクセスしなくてはならない点に難しさがありました。
これらの課題を一挙に解決したのが、Asyncifyという技術です。この技術を使うと、WASM上で通常行えない特殊なフロー制御が行えるようになります。Asincifyをうまく使うことで、3つの課題を解決できたとのことです。
他にも、RubyのソースコードをRubyインタプリタを同梱できるようにするために、wasi-vfsを開発したそうです。WASIで仮想のファイルシステムを操作できるようにすることで、Rubyソースコードの同梱を実現したそうです。
まとめ
より詳しくは、下記の記事で詳しく解説されています。
An Update on WebAssembly/WASI Support in Ruby | by kateinoigakukun | ITNEXT
RubyVM::AbstractSyntaxTreeを使ってソースコード内のデータを引っ張り出す
下記のようなソースコードdata.rbがあったとする
build([1, 3, 7, 0, 1, 3])
このソースコードでbuildに渡している引数の合計を、外部から取得して合計を求める。
code = File.read('data.rb') root = RubyVM::AbstractSyntaxTree.parse(code, keep_script_lines: true) args = nil eval "args = #{root.children[2].children[1].source}" args.sum # => 15
keep_script_lines: trueを指定するのがミソ。このオプションを指定してパースすると、ノードから#sourceを利用して元のソースコードを得ることができる。スゴイ。
まだ隠し機能らしく、ドキュメントの記載は薄い。 https://docs.ruby-lang.org/en/3.1/RubyVM/AbstractSyntaxTree.html
やりすぎないドメイン駆動設計 on Rails
ドメイン駆動設計(DDD)では、Springのようにドメインをほかの関心事(データソース、プレゼンテーション)から分離したフレームワークが用いられることが多です。一方で、Ruby on Railsは、ドメインとデータソース層が密に結合しており、DDDには向いていないと考えられています。
Railsでドメイン駆動設計をする大変さ
それでも、アーキテクチャに手を加えることで、Railsでもドメイン駆動設計を行った事例が公開されています。以下の取り組みでは、Railsの提供するActive RecordをDAOとして利用してドメインを分離することで、ドメインを切り出しやすくしています。
ドメイン駆動設計の比類なきパワーでRailsレガシーコードなど大爆殺したるわあああ!!! - Qiita
Railsにおけるドメイン駆動設計の実践 · Linyclar
Railsでドメイン駆動設計を行う上での課題は、ドメインオブジェクトがデータソース層(ActiveRecord)から分離できていない点にあります。 ドメインオブジェクトにドメイン以外の知識が入り込むことを防ぐことで、柔軟なモデルを作ることができるとされています。
このため、例に挙げた取り組みでは、ActiveRecordとドメインオブジェクト用のクラスを分離する、アプローチをとっています。ドメインオブジェクトを利用するときは、ActiveRecordから得た値を使ってドメインオブジェクト生成します。ドメインオブジェクト生成用の値の詰め替え処理は、自前で書いていくことになるので結構骨の折れる作業になります。
また、Railsの開発効率の核となるActiveRecordのメソッドがコントローラやViewから使えなくなります。これも大きな痛みを伴う点です。
反対に、hanamiやSpringでは、クリーンアーキテクチャで示されるような、ドメインモデルをDBやUIから分離する構成を比較的簡単に実現できます。
密結合なアーキテクチャでDDDをやってはダメなのか
ドメイン駆動設計で何を得たいのか、というと、主には下記の二つが挙げられます。
- 変更容易性
- ドメインの知識が反映されたソフトウェアのモデル
クリーンアーキテクチャでは、ドメインモデルがほかの要素から分離されたつくりにすることで、上記二つの効果を高めています。
一方で、Railsのような密結合なアーキテクチャで、ドメイン駆動設計をしたとしても、上記の効果は部分的ではありますが得ることができます。
部分的にドメインオブジェクトを使う
Railsのアーキテクチャを壊さないままドメインモデルを表現しようとするととどうなるでしょうか?
ActiveRecordと重なるドメインオブジェクト
ActiveRecordは、ドメインオブジェクトとデータソースの両方の性質を併せ持つオブジェクトです。 このため、ActiveRecordはそのままドメインオブジェクトとして扱えます。
ActiveRecordでないドメインオブジェクト
ActiveRecordではないドメインオブジェクトは、下記のようなものが考えられます。
- あるActiveRecordをもとに構成されるが、異なる構造をもつドメインオブジェクト
- ActiveRecordのプロパティの一部から構成されるドメインオブジェクト
どちらの場合も、必要な時だけドメインオブジェクトにする、というアプローチが取れます。
読み込むときは、下記のようにします。
class Address
attr_accessor :prefecture, :postal_code, :address_detail
def domain_logic; end
end
# usersテーブルに、prefecture, postal_codeなどをもつ
class User < ActiveRecord
def address_as_object
Address.new(prefecture, postal_code, address_detail)
end
end
書き込むときはこのようになメソッドを生やせばよいです。もし、この変換処理が複雑で分離する必要があるなら、Repositoryを適宜つくります。
class Client
def save
self.to_user.save
end
def to_user
User.find_or_initialize_by(id: id,...)
end
end
部分的に作ってうれしいのか
みんなアーキテクチャをごっそり変えてDDDしているのに、こんな中途半端な使い方で大丈夫か、と思うかもしれません。 DDDの核となる考えは、ドメインの知識を反映したモデルを作ることで、ドメインに対する洞察と変更容易性を得ることです。
たとえ部分的であっても、ドメインオブジェクトを作って使うことでその効果は得られます。
この方法の利点は、ActiveRecordの世界観をできるだけ壊さずに、ドメインモデルを使うことができる点です。 ドメインモデルをほかの層から分離することによるアーキテクチャの柔軟性は得られません。
既存のRailsアプリケーションで、特に複雑な部分から少しずつドメイン知識をコード化していくときに向いている手法だと考えます。
つらくなったら
つらくなったらアーキテクチャからごっそり変えて、ドメインを分離しましょう。 あるいは、ActiveRecordを普通に使ったほうが嬉しいと感じたら、またどこかのActiveRecordかコントローラにロジックを戻してあげましょう。後戻りはおそらく簡単なはずです。